目的・背景
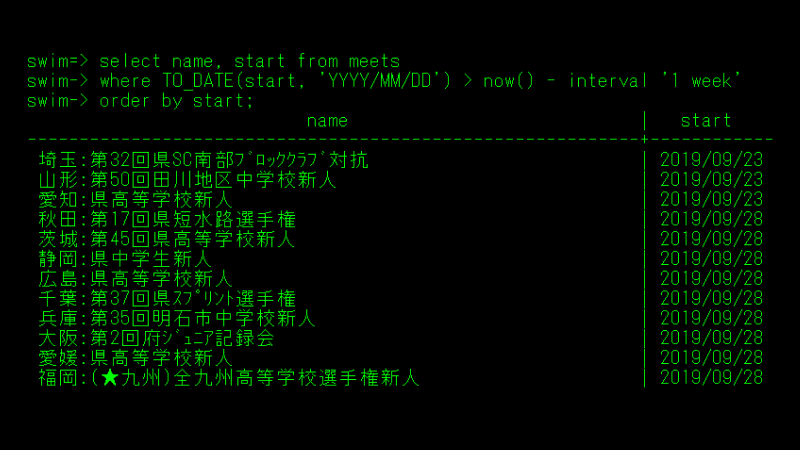
スイマーズゼロで使用する水泳のレースデータを自動的に取得するために開発しました。最新のデータを使用したいため、毎日早朝に自動的にスクレイピングを開始するようにしています。スクレイピング先は日本水泳連盟公式の旧記録掲載サイトで、静的なHTMLで構成されています。スクレイピングにはPythonのBeautiful Soup(BS4) を使用しました。
工夫点・苦労した点
正規表現でデータを探す
探索対象のリンクや大会情報(日付・場所など)は一定のルールに基づいて書かれています。これらから情報を抜き取るため、正規表現を学びました。繰り返しパターンマッチングさせるため、事前にパターンをコンパイル(re.compile())することで高速化を図っています。
細かい分岐の繰り返し
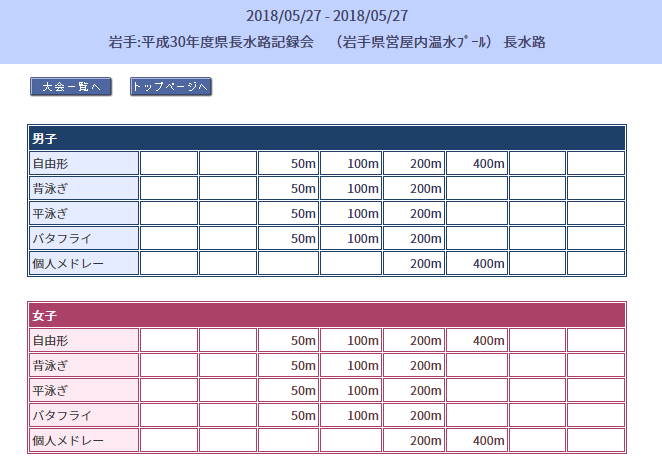
中には例外的な文書構造のページもあります。例えばリレー種目と個人種目とでは、文書のtable要素の設計が異なります。通常の個人種目では3列目に存在していたデータでも、リレー種目のページでは4列目になることがあります。こうした細かい例外にも対応し、適切にデータを読み取るために入念に分岐処理を組み込んでいます。
完璧な同一人物の判定が不可能
取得できるデータにはIDが振られていません。特に選手を識別するIDがないことが、このシステムで最も苦しかった点です。初期は氏名の漢字フルネームが一致していれば同一人物のデータとみなしていましたが、日本全国を範囲にすると大量の同姓同名の選手がいることに気づきました。それを受け、最終的には同姓同名かつ同一年度にて同一学年であれば同一人物と扱うことにしました。この方法でもかなり問題がありました。まずやはり同一年齢で同姓同名の水泳選手も、中には存在したようです。(ユーザーからの報告により知りました)また同一人物でも漢字に表記ゆれが発生すると(たとえば「柳」と「栁」など)別人物として扱われてしまいます。所属チームや出場大会会場、タイムのレベルなどをもとに判別することも考えられましたが、これらの属性はあまりにも変動が大きい(たとえば一人が複数のチームに所属することもあれば、地方と東京の両方の大会に出場することもある)ため実装できませんでした。
年度をまたいだ同一人物判定はさらに困難
氏名と学年による判定方法では、年をまたいだ場合にさらに効力が弱まります。たとえば2018年に高校3年生だった佐藤太郎選手と2019年に大学1年生だった佐藤太郎選手は本当に同一人物でしょうか?9割がたそうですが、そうとは断定することはできません。高校3年生の次の年は高校4年生の場合もあります(高専などの場合)。浪人してデータがないことも考えられるでしょう。2019年の佐藤太郎さんは別人物で、大学から水泳を始めた人かもしれません。このように様々なパターンが考えられるため、同一人物判定のアルゴリズムは複雑さを極めました。それでも結局は推測で、「本当に100%正しいデータだ」と断言できないことが大変悔しかったです。
チーム名の表記ゆれ
同一人物判定と同じく、同一チームの判定においても同じように苦しめられました。たとえば慶應義塾大学なら、「慶應義塾大学」「慶應義塾大」「慶應大学」「慶應」など複数の表記が見られます。なんらかの指標をチームごとに集計したい場合、この表記ゆれを統一しなくてはなりません。しかし結局これらの判定を全国全ての学校、水泳クラブを対象に行うのは極めて難しく、チーム名に関しては一意のIDを振ることはありませんでした。
フォーマットの不均一な「汚い」データ
肝心のレースのタイムでさえも簡単に取得はできませんでした。数字が全角だったり、不要なスペースが挿入されていたり、本来存在するはずのタイムがなかったりすることが最も多かったです。そしてタイムのフォーマットも不規則なことがありました。1:03.81なら、「1.03.81」「1-03.81」「1:3.81」といった様々なパターンがあります。これらも正しく認識・変換しなくてはなりませんでした。場合によっては完全に無効なデータ(世界記録よりも速いタイムや1:72.82などの記録ミスと思われるもの)もあり、それらは手作業で修正・削除をしていました。